
与时俱进,诚赢客户
十年散热器、离心风机、压缩机制造厂家
全国服务热线400-123-4567
本文章将介绍解决凸优化问题中常用到的几种算法,这几种算法都是基于迭代的思想进行求解,以下把这些迭代算法简称为优化算法。此外,还介绍了关于优化算法中解的性质[1]。
首先在介绍优化算法时,把凸优化问题分为了无约束优化问题和有约束优化问题,对应的优化算法也会有所不同,但算法的基本框架都是基于迭代来求解,因此首先介绍算法的基本思想。
优化算法的基本迭代公式:
其中
上式可以看出, 由
、步长和方向决定,
是上一步的结果,因此难点在于如何确定合适的步长
,以及如何确定一个能让函数值下降的方向
。
例1:下面是函数 在(2,3)处所有能使函数下降的方向。为了更加直观地表示某一点处函数下降的所有方向,我们可以在该点处画出一个球体,并在球体表面上标注出使函数下降的方向。
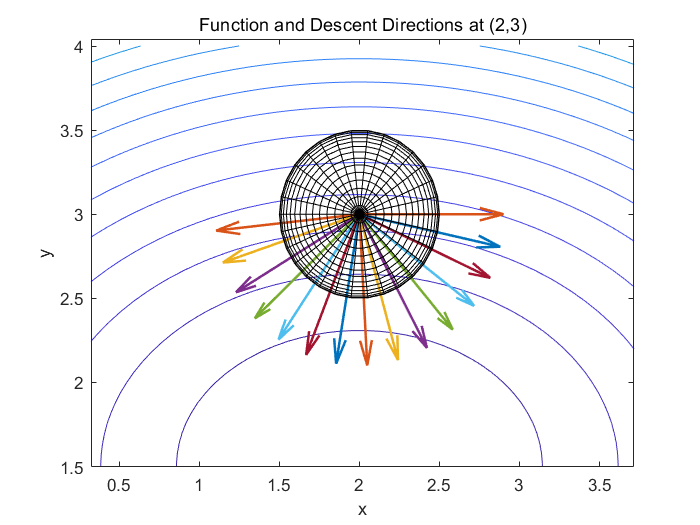
在确定步长的目标是让每一步的 与
相乘后使得目标函数尽可能的小,数学表达即为:
由于
和
都已知,因此这是一个一维线性搜索问题。介绍下面两种不精确算法:
上述就是迭代算法的基本思想,在介绍如何确定方向之前,我们先考虑此类迭代算法的性能该如何评估?换句话说收敛性如何?为此,下节将介绍函数的一些性质,帮助我们分析算法的收敛性。
对于一般的无约束优化问题且 f(x) 一阶可微,根据KKT条件,最优性条件就为
。那自然地会考虑,当
时,
以及
他们之间的差距如何刻画?由于迭代算法本质上是一步步去逼近最优解,得到第 k 步的解必然会与最优解存在一点的差距,那么如何来分析第 k 步的解离最优解的距离?此外,如何分析最优值
离
的距离?其实后者问题,即
更具有实践意义,因为优化本质要找到目标函数的最小值。比如一些实际情况,
离
还很远,但经过 k 步迭代后得到目标函数值已经非常接近最小值了,并且该值在一定程度下已经可以满足工程实践意义,那么我们就可以让迭代停止了,没必要花更多的时间去逼近最优解。因此,为了能帮助我们更好的刻画这种差距,下面将引入函数的强凸性的概念。
强凸性定义:假设 二阶可微,其强凸性有如下定义:
即 是半正定矩阵。
如何理解上式?首先给出一个直观的解释:目标函数的强凸性指的是函数的曲率足够强,也就是说,函数图像在任意两点之间的下凸壳都被上方的某个超平面所包含。具体来说,对于一个凸函数 ,如果存在一个正实数
,使得对于
和
,都有:
其中 是
和
之间的欧几里得距离。这个不等式一阶形式可以表示成:
其中 表示
在
处的梯度。
假设函数是强凸的,我们来看看对我们的分析会有什么帮助?比如当,
会不会趋于
,或者说还有多少的差距?
(1)分析最优解 与近似解的距离。
对于 ,只分析式(6)的右边有:
可以看出,式(7)是一个关于 y 的凸函数。自然的想到,如果能求出(7)的最小值,是不是能得到 的一个下界?因此,根据凸函数求最小的最优性条件,一阶偏导等于0,首先求驻点方程(对 y 偏导)有:
有 ,上面操作的目的是为了找到使得式(7)值最小的一个 y,把
代回(7),可以的得到
的下界:
目前为止,我们得到一个结论:如果一个函数是强凸的,一定有(8)成立;同时这个式子对于 和
也是成立的。因此可以把
取为目标函数
的最优解
,把
记为
,上式可变为:
对上式做一个移项,又已知对于 ,
一定有一个下界
,因此有下述不等式成立:
由于我们想知道 与
之间的关系,因此再做一次变换有:
假设 ,代入后我们就得到了第 k 步函数值与最优值
距离的上界。这里解释一下,为什么
需要加一个二范数。首先由于
一定大于或等于
,因此
一定是大于或等于 0 的,同时
与
都是一维的,因此实际上
。但二范数实际上表示了欧几里得距离,能更好地表达之前我们所说的最优值和第 k 步函数值之间的差距。
回到最初的问题,当 ,两个解的差距是多少?可以看出,如果知道
在
处的梯度,虽然我们不能得到一个精确的距离,但知道这个距离一定存在一个上界,就是
。同时,当
时,
也就趋近于
。
下面证明用到了柯西施瓦茨不等式内积形式: ,把
代入有:
,即
。由柯西-施瓦茨不等式
,有:
首先,假设函数是强凸的,当 时有:
重新整合上式得到:
因为 ,消去一个后有:
从上述推导可以看出,假设 是给定的,如果
是一个非常大的数,也就是说该函数是一个非常强凸的函数,可以看到
,
这两项都非常小,说明非常接近最优解了,也非常接近最优值了。但如果
非常小,即使
,此时的解距离最优解和最优值还有很大差距。通过上述的证明,可以得到两条性质:
(1)对于一个无约束的优化问题的优化算法,基本思路都是让一阶偏导等于0,也相当于在解一个退化后的KKT条件。同时,利用函数的强凸性,我们可以刻画迭代后得到解的精确程度,利用上述结论可以来量化第k步解与最优解的损失程度。
(2)函数的凸性越强,越容易收敛到最低点。
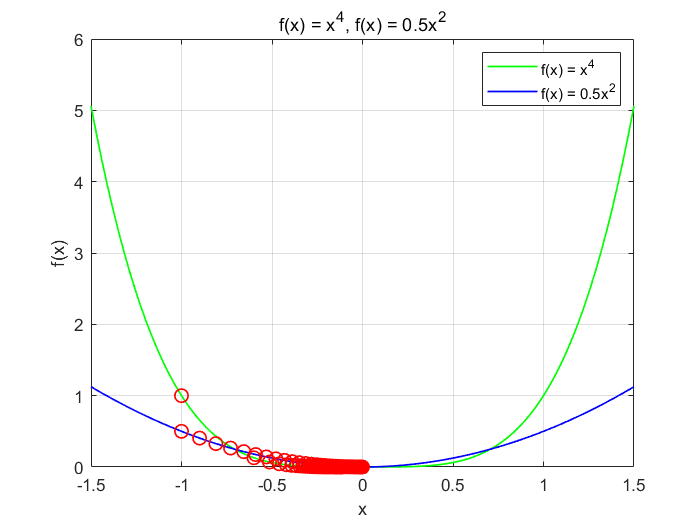
例2:为了能直观的解释函数的强凸性,用两个不同强凸性的函数在梯度下降优化时的表现来说明。
绿色是函数 的优化轨迹,蓝色是函数
的优化轨迹。
比
的曲率更大,凸性更强。可以看到,两个函数在初始点处的梯度大小是相同的,但是
函数的优化过程更快,而且更不容易陷入局部最优。
假设 二阶可微,函数强凸性的上界有如下定义:
即 是半负定矩阵。显然,和前面的强凸性相比,
。
同样的,另一个等价的定义, ,有
对应的有下述性质:
通过强凸性上界的定义,给出了最优值与第k步函数值的距离的下界。该性质说明了当
很大时,
距离最优解还很远。







