
与时俱进,诚赢客户
十年散热器、离心风机、压缩机制造厂家
全国服务热线400-123-4567
本系列博客将结合开发者个人经验和相关书籍介绍,从编译器优化、高效使用C++、面向硬件优化和profiling工具等几个方向,对C++的性能优化做总结介绍。介绍性能优化过程中,不免涉及到实例代码及其编译运行,这些示例将通过compiler explorer(Compiler Explorer)和onlinegdb.com的链接方式给出。
在面对一个对性能要求高的复杂C++工程而言,对它的性能优化应该从哪开始着手进行?我们认为首先需要对程序的运行性能做分析,即:
有了以上分析后,根据profiling工具给出的性能分析,就可以开始对我们的程序做性能优化了。
提升C++程序的性能有很多手段,整体而言可以概括为以下三类:
在代码编写阶段,有一些设计实现可以帮助我们编写高性能代码,开发者可能作为guideline参考:
三类优化手段分为三节进行阐述,第一节选先介绍编译器优化使用这一主题。
给编译器设置目标平台选项,可以让编译器根据设定的cpu-type微架构生成特定优化的代码,在GCC/LLVM上也可以使用"native"让编译器自动检测架构特性进行优化。需要注意的是,由于采用了架构特有的优化,这样优化生成的代码可能出现跨机器运行问题,这也是编译器默认并未使用该选项的原因,虽然这一项优化可以为一些计算密集型的程序带来非常不错的性能提升。
不同编译器使能选项:
| X86 GCC/LLVM | -march=native -mtune=native 指定-march后,-mtune选项默认和-march相同,除非特别指定-mtune |
| X86 MSVC | /arch:SSE or /arch:SSE2 or /arch:AVX or /arch:AVX2 or /arch:AVX512 |
| ARM GCC/LLVM | -mcpu=native |
| ARM MSCV | /arch: xxx |
对于一些对计算精度要求低、计算性能要求高的场景,使用fast-math库是一个可选项,fast-math的计算结果可能和标准不一致。
在GCC/LLVM中,使用"-ffast-math"使能编译优化,该选项包含在"-Ofast"选项中;MSVC使用"/fp:fast"选项使能。
GCC/LLVM中使用"-fno-exceptions"选项禁用异常,该选项对所有使用"throw"抛出异常的地方,替换为std::abrot()调用,参考GCC说明:Exceptions。禁用后的好处是编译器不再生成异常处理相关的代码,
但是,在现代C++中,异常的使用对于正常运行的代码基本没有开销,抛出异常并处理带来的性能开销非常小(<3%),所以对于非关键性能实现,可以不考虑禁用异常。以上分析来自(Standard C++):
“But exceptions are expensive!” Not really. Modern C++ implementations reduce the overhead of using exceptions to a few percent (say, 3%) and that’s compared to no error handling. Writing code with error-return codes and tests is not free either. As a rule of thumb, exception handling is extremely cheap when you don’t throw an exception. It costs nothing on some implementations. All the cost is incurred when you throw an exception: that is, “normal code” is faster than code using error-return codes and tests. You incur cost only when you have an error.
RTTI用于为运行时提供类型信息,使用"-fno-rtti"选项将不再为包含虚函数的类生成额外的类型信息,这些类型信息会被C++中的dynamic_cast和type_id使用,但是禁用该特性对多态、虚函数的使用没有影响,因此禁用RTTI对编码的影响较小。
GCC/LLVM使用"-flto"编译选项使能链接时优化,这其中包括内联优化、程序间分析(IPA)和程序间优化(IPO)等。
Unity build的主要目标是提高编译效率,将多个文件合并为一个文件也能为编译器提供更多的优化机会。

CMake为Unity Build提供了支持,使用"-DCMAKE_UNITY_BUILD=ON"选项使能。
动态链接有很多优势:更节约内存空间,替换更加方便,可以运行时加载特定模块运行;但是动态链接也带来了运行时的性能开销,据《程序员的自我修养:链接、装载与库》的统计,静态链接大概可以得到5%左右的性能提升。
不同编译器和库对程序的优化效果不同,对于Linux上的程序开发而言,不妨尝试一下clang和gcc的编译和库,选择其中更优的版本。
使用特定的动态链接库对程序运行做优化,例如使用更快的malloc库进行替换:
env LD_PRELOAD=/usr/lib/libSUPERmalloc.so https://zhuanlan.zhihu.com/p/your-programBinary后处理工程是在编译链接完成后,通过修改程序代码的布局提升运行性能,常见的工具如bolt,相关论文显示优化后的程序性能可以提升20%,主要得益于ICache和页面缓存的利用。其使用方式参考:https://github.com/llvm/llvm-project/blob/main/bolt/README.md
constexpr是C++11引入的特性,对于变量,constexpr表明一个值不仅仅是常量,还是编译期可知的;对于函数,由于实参是编译期常量,则函数将产生编译器常量,如果实参是运行时才能知道的值,它们就将产出运行时值。
constexpr int foo(int x) { return x + 42; }
constexpr int val = foo(100); // Compile time
int x;
std::cin >> x;
int res = foo(x); // Runtime
判断一个函数调用是否是编译期完成:
if (std::is_constant_evaluated()) { ... }
if consteval { ... } // From C++23,注意与constexpr if的区别
为了更好地进行编译器优化,C++20引入了consteval(更严格的constexpr):只能用于函数的声明,且函数一旦被声明为consteval后,所有调用的实参必须是常量表达式。
// 例子来自:https://zhuanlan.zhihu.com/p/350429113
consteval int sqr(int x) {
return x * x;
}
void foo() {
constexpr const int x = 10;
int y = doSomething();
sqr(x); // OK, sqr(x) is constant expression
sqr(y); // Error: sqr(y) is not a constant expression
}
struct _internal_state {
bool fill
};
void draw_mesh(const Mesh* m) {
for (const Node* n = m->begin(); n != m->end(); ++n) {
if (__internal_state.fill) {
...
} else {
...
}
}
}
上述代码中,将全局变量__internal_state.fill copy为const局部变量,如下:
void draw_mesh(const Mesh* m) {
const bool is_fill = __internal_state.fill; // 将全局变量__internal_state.fill copy为const局部变量
for (const Node* n = m->begin(); n != m->end(); ++n) {
if (is_fill) {
...
} else {
...
}
}
}
void f(); // 可能抛出异常
void f() noexcept; // 不会抛出异常使用noexcept修饰后,可以让编译器省去生成的异常处理代码,有很多的优化机会。
noexcept对于移动语义,swap,内存释放函数和析构函数非常有用
在定义函数时,如果函数仅在文件内调用,将函数定义为static,可以让编译器更好进行inline优化。
代码示例:
使用inline hint:
static linkage函数版本:Compiler Explorer - C++ (x86-64 gcc 12.2)
external linkage版本:Compiler Explorer - C++ (x86-64 gcc 12.2)
示例(Compiler Explorer - C++ (x86-64 gcc (trunk))):
bool require_init = true;
void init_lib();
void build_lib();
void internal_work();
void work()
{
if (require_init) {
init_lib();
require_init = false;
} else [[likely]] {
build_lib();
require_init = true;
}
internal_work();
}
以上这段代码,如果不加"[[unlikely]]"修饰,生成的汇编:
// 不添加likely,生成的调用是call init_lib()
work():
sub rsp, 8
cmp BYTE PTR require_init[rip], 0
je .L2
call init_lib()
xor eax, eax
mov BYTE PTR require_init[rip], al
add rsp, 8
jmp internal_work()
.L2:
call build_lib()
mov eax, 1
mov BYTE PTR require_init[rip], al
add rsp, 8
jmp internal_work()
require_init:
.byte 1
// 添加likely,生成的调用是call build_lib()
work():
sub rsp, 8
cmp BYTE PTR require_init[rip], 0
jne .L6
call build_lib()
mov eax, 1
mov BYTE PTR require_init[rip], al
add rsp, 8
jmp internal_work()
.L6:
call init_lib()
xor eax, eax
mov BYTE PTR require_init[rip], al
add rsp, 8
jmp internal_work()
require_init:
.byte 1
各类编译器都支持了类似C++23 assume的特性,该特性用于告诉编译器某个condition一定成立,编译器可以据此进行优化,如果condition不满足,则可能产生undefined behavior。
| C++23 | [[assume(condition)]]; |
| GCC | if (!condition) __builtin_unreachable(); |
| LLVM | __builtin_assume(condition); |
void limiter(float* data, size_t size) {
[[assume(size > 0)]];
[[assume(size % 32==0)]];
for (size_t i = 0; i < size; ++i) {
[[assume(std::isfinite(data[i]))]];
data[i] = std::clamp(data[i], -1.0f, 1.0f);
}
}
第一个是假设size永不为0,总是正数;第二个告诉编译器size总是32的倍数;第三个表明数据不是NaN或无限小数。
这些假设不会被评估,也不会被检查,编译器假设其为真,依此优化代码。若是假设为假,可能会产生UB。
assume和assert有些类似,他们的异同在于:
| assume | assert |
|---|---|
| condition必须是true | condition必须是true |
| 提供给compiler进行优化 | 提供给程序员,标识条件必须成立 |
| 如果条件不成立,则可能产生undefined behavior | 如果条件不成立,在未定义NDEBUG时执行std::abort()中断程序,否则作为nop处理 |
值得一提的是,类似的还有GCC的"__builtin_unreachable()"特性,可以用于提示编译器该分支不会执行,从而进行优化,否则触发未定义行为。
使用__restrict的示例:Compiler Explorer - C++ (x86-64 clang (trunk))
void my_memcpy(void* __restrict dest, void* __restrict src, size_t size) {
for (size_t i = 0; i < size; ++i) {
((char*)dest)[i] = ((char*)src)[i];
}
}
以上代码中,使用__restrict标识在该指针的生命周期内,其指向的对象不会被别的指针所引用,可以为编译器提供更好的优化,直接调用标准库中的memcpy;相反的,如果去掉__restrict关键字,则可能生成一系列的实现代码。
传参的形式参考下列二叉树:
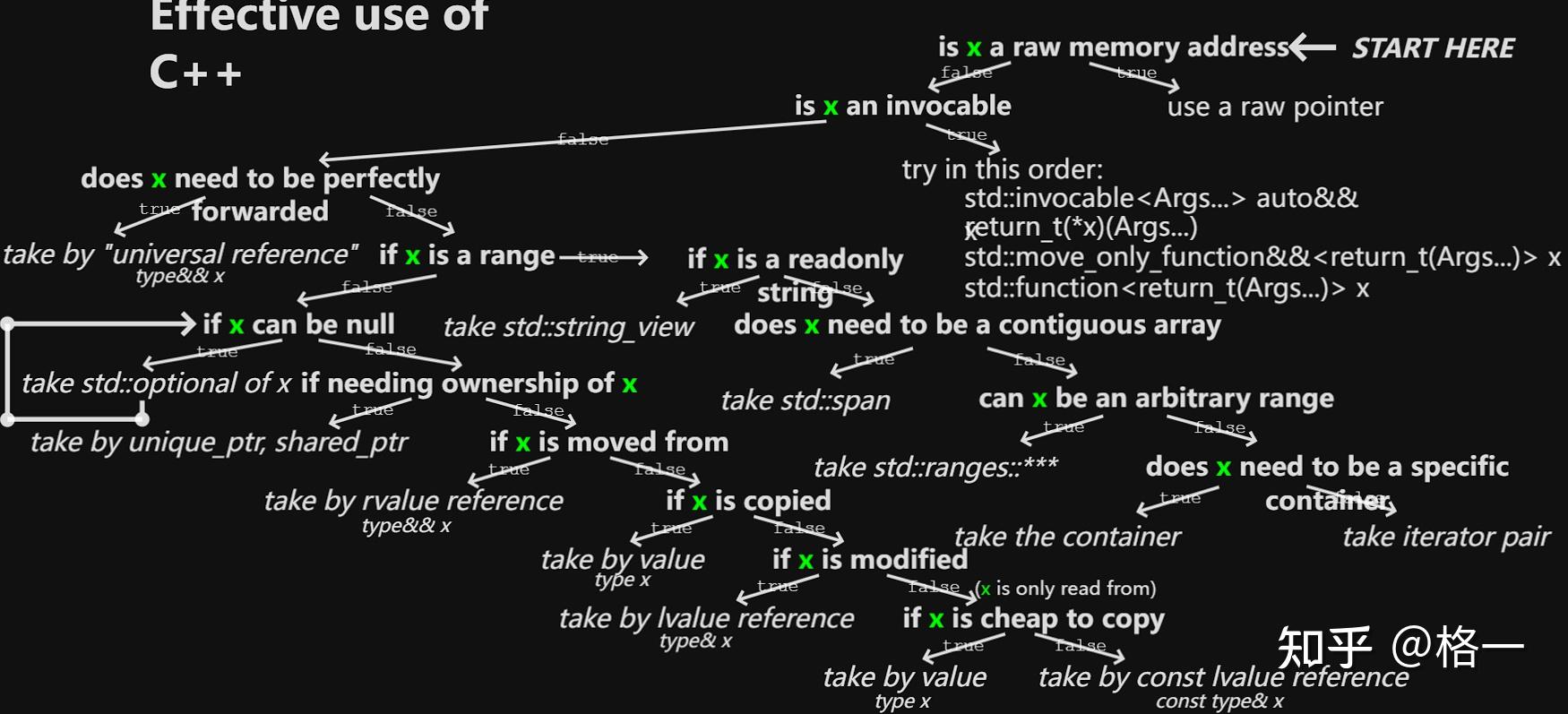
此外,对于常见的字符串传递,建议使用std::string_view。const string&和const char*存在以下问题:
void foo(const string& s);
foo("hello");
上述代码中,字面量"hello"将进行隐式转换,构造string对象,影响性能。
void foo(const char* s);
foo(str.c_str());
foo(std::string("hello").c_str())
上述代码中,需要为每个string对象调用c_str()获取指针;而string_view可以较好解决这两个问题,而且string_view非常轻量,内部仅维护了指向字符串的指针和size。
void foo(std::string_view sv);
foo(std::string("hello"));
foo("Hello");
如下示例代码中,while循环内部每次都会创建string对象,可以将对象的创建放到循环外:
// -> std::string line; // move here
while (true) {
std::string line;
std::getline(std::cin, line);
if (!std::cin)
break;
process_line(line);
}
另外一个例子是,对于可预测size的vector,建议使用reserve()提前创建好对应空间:
std::vector<int> shiny;
// shiny.reserve(100); // Add a reserve here
for (int i = 1; i <= 100 ++i)
if (is_shiny(i))
shiny.push_back(i);
C++11引入std::move、std::forward后,关于右值引用、移动语义和完美转发,可以参考《Effective C++》中的介绍:
Effective Modern C++move在一些需要copy的场景中使用移动语义进行替代,例如使用move constructor代替copy constructor,避免不必要的拷贝构造和销毁:
template <class T>
swap(T& a, T& b) {
T tmp(a); // we've made a second copy of a
a = b; // we've made a second copy of b (and discarded a copy of a)
b = tmp; // we've made a second copy of tmp (and discarded a copy of b)
}
使用move的版本如下:
template <class T>
swap(T& a, T& b) {
T tmp(std::move(a));
a = std::move(b);
b = std::move(tmp);
}
假如传入的参数是vector<int>,那么move版本可以避免拷贝构造中n个元素的复制(3 * n),而move版本只是进行了三个指向vector buffer指针的读写,以及buffer size的操作。
int matrix[rows][cols];
for (int row = 0; row < rows; ++row)
for (int col = 0; col < cols; ++col)
process(matrix[row][col]);
由于CacheLine和Cache的预取,上述代码要比以下代码更加友好:
int matrix[rows][cols];
for (int col = 0; col < cols; ++col)
for (int row = 0; row < rows; ++row)
process(matrix[row][col]);
由于Core的L1/L2 Cache是私有的,发生线程切换后可能造成Cache被替换,可以使用以下API将线程绑定至特定的Core,更好利用时间局部性。
| Linux | pthread_set_affinity |
| Windows | SetThreadAffinityMask |
还可以利用以下API设置进程的优先级:
| Linux, macOS | setpriority |
| Windows | SetPriorityClass |
设置线程的优先级:
| Linux | pthread_setschedprio |
|---|---|
| Windows | SetThreadPriority |
以上这些API的调用都可能影响OS的调度,使用时需要注意对其他进程的影响。
现代处理器都提供了SIMD扩展,这部分对于计算密集型程序的提升非常巨大。
compiler explorer:Compiler Explorer
在线编程并运行:https://www.onlinegdb.com/online_c++_compiler
上述视频的slides:https://slides.com/janekb04/your-performance-todo-list/#/5/0/1
C++11 feature介绍:https://oraclechang.files.wordpress.com/2013/05/c11-a-cheat-sheete28094alex-sinyakov.pdf
C++17 reference card:https://github.com/tpn/pdfs/blob/master/C%2B%2B17%20Language%20Features%20Reference%20Card%20(2019).pdf
C++20 reference card:https://github.com/tpn/pdfs/blob/master/C%2B%2B20%20Reference%20Card%20-%2029th%20Jan%202020.pdf







