
与时俱进,诚赢客户
十年散热器、离心风机、压缩机制造厂家
全国服务热线400-123-4567
目录
█?协调器和队列运行器(Coordinator and QueueRunner)
本文所讲的内容主要为以下列表中相关函数。函数training()通过梯度下降法为最小化损失函数增加了相关的优化操作,在训练过程中,先实例化一个优化函数,比如 tf.train.GradientDescentOptimizer,并基于一定的学习率进行梯度优化训练:
然后,可以设置 一个用于记录全局训练步骤的单值。以及使用minimize()操作,该操作不仅可以优化更新训练的模型参数,也可以为全局步骤(global step)计数。与其他tensorflow操作类似,这些训练操作都需要在tf.session会话中进行
| 操作组 | 操作 |
|---|---|
| Training | Optimizers,Gradient Computation,Gradient Clipping,Distributed execution |
| Testing | Unit tests,Utilities,Gradient checking |
一个TFRecords 文件为一个字符串序列。这种格式并非随机获取,它比较适合大规模的数据流,而不太适合需要快速分区或其他非序列获取方式。
tf中各种优化类提供了为损失函数计算梯度的方法,其中包含比较经典的优化算法,比如GradientDescent 和Adagrad。
class tf.train.Optimizer
| 操作 | 描述 |
|---|---|
| class tf.train.Optimizer | 基本的优化类,该类不常常被直接调用,而较多使用其子类, 比如GradientDescentOptimizer, AdagradOptimizer 或者MomentumOptimizer |
| tf.train.Optimizer.__init__(use_locking, name) | 创建一个新的优化器, 该优化器必须被其子类(subclasses)的构造函数调用 |
| tf.train.Optimizer.minimize(loss, global_step=None,? var_list=None, gate_gradients=1,? aggregation_method=None, colocate_gradients_with_ops=False,? name=None, grad_loss=None) | 添加操作节点,用于最小化loss,并更新var_list 该函数是简单的合并了compute_gradients()与apply_gradients()函数 返回为一个优化更新后的var_list,如果global_step非None,该操作还会为global_step做自增操作 |
| tf.train.Optimizer.compute_gradients(loss,var_list=None, gate_gradients=1, aggregation_method=None,? colocate_gradients_with_ops=False, grad_loss=None) | 对var_list中的变量计算loss的梯度 该函数为函数minimize()的第一部分,返回一个以元组(gradient, variable)组成的列表 |
| tf.train.Optimizer.apply_gradients(grads_and_vars, global_step=None, name=None) | 将计算出的梯度应用到变量上,是函数minimize()的第二部分,返回一个应用指定的梯度的操作Operation,对global_step做自增操作 |
| tf.train.Optimizer.get_name() | 获取名称 |
class tf.train.Optimizer?
用法
在使用它们之前处理梯度?
使用minimize()操作,该操作不仅可以计算出梯度,而且还可以将梯度作用在变量上。如果想在使用它们之前处理梯度,可以按照以下三步骤使用optimizer :
例如:
一些optimizer的子类,比如 MomentumOptimizer 和 AdagradOptimizer 分配和管理着额外的用于训练的变量。这些变量称之为’Slots’,Slots有相应的名称,可以向optimizer访问的slots名称。有助于在log debug一个训练算法以及报告slots状态
| 操作 | 描述 |
|---|---|
| tf.train.Optimizer.get_slot_names() | 返回一个由Optimizer所创建的slots的名称列表 |
| tf.train.Optimizer.get_slot(var, name) | 返回一个name所对应的slot,name是由Optimizer为var所创建 var为用于传入 minimize() 或 apply_gradients()的变量 |
| class tf.train.GradientDescentOptimizer | 使用梯度下降算法的Optimizer |
| tf.train.GradientDescentOptimizer.__init__(learning_rate,? use_locking=False, name=’GradientDescent’) | 构建一个新的梯度下降优化器(Optimizer) |
| class tf.train.AdadeltaOptimizer | 使用Adadelta算法的Optimizer |
| tf.train.AdadeltaOptimizer.__init__(learning_rate=0.001,? rho=0.95, epsilon=1e-08,? use_locking=False, name=’Adadelta’) | 创建Adadelta优化器 |
| class tf.train.AdagradOptimizer | 使用Adagrad算法的Optimizer |
| tf.train.AdagradOptimizer.__init__(learning_rate,? initial_accumulator_value=0.1,? use_locking=False, name=’Adagrad’) | 创建Adagrad优化器 |
| class tf.train.MomentumOptimizer | 使用Momentum算法的Optimizer |
| tf.train.MomentumOptimizer.__init__(learning_rate,? momentum, use_locking=False,? name=’Momentum’, use_nesterov=False) | 创建momentum优化器 momentum:动量,一个tensor或者浮点值 |
| class tf.train.AdamOptimizer | 使用Adam 算法的Optimizer |
| tf.train.AdamOptimizer.__init__(learning_rate=0.001, beta1=0.9, beta2=0.999, epsilon=1e-08, use_locking=False, name=’Adam’) | 创建Adam优化器 |
| class tf.train.FtrlOptimizer | 使用FTRL 算法的Optimizer |
| tf.train.FtrlOptimizer.__init__(learning_rate,? learning_rate_power=-0.5,? initial_accumulator_value=0.1,? l1_regularization_strength=0.0,? l2_regularization_strength=0.0, use_locking=False, name=’Ftrl’) | 创建FTRL算法优化器 |
| class tf.train.RMSPropOptimizer | 使用RMSProp算法的Optimizer |
| tf.train.RMSPropOptimizer.__init__(learning_rate,? decay=0.9, momentum=0.0, epsilon=1e-10,? use_locking=False, name=’RMSProp’) | 创建RMSProp算法优化器 |
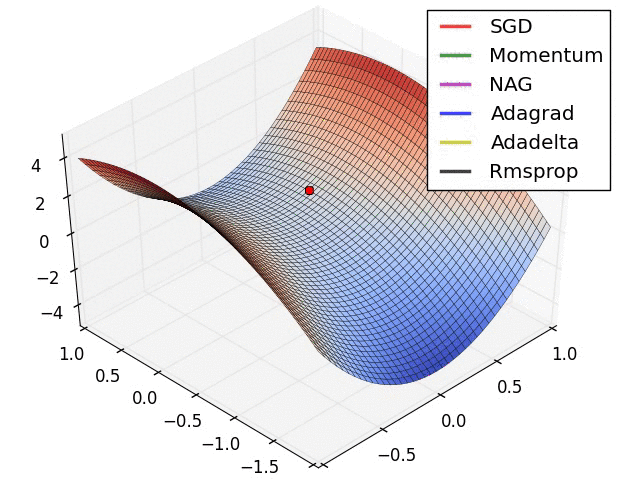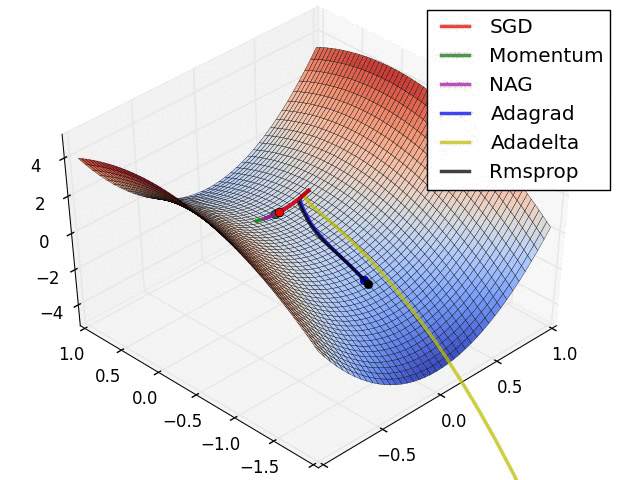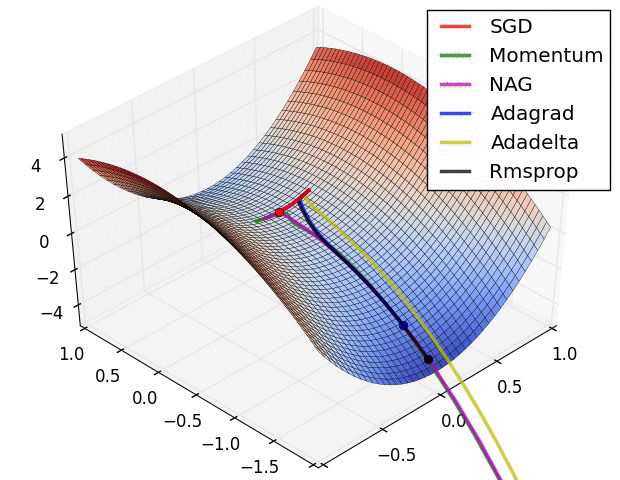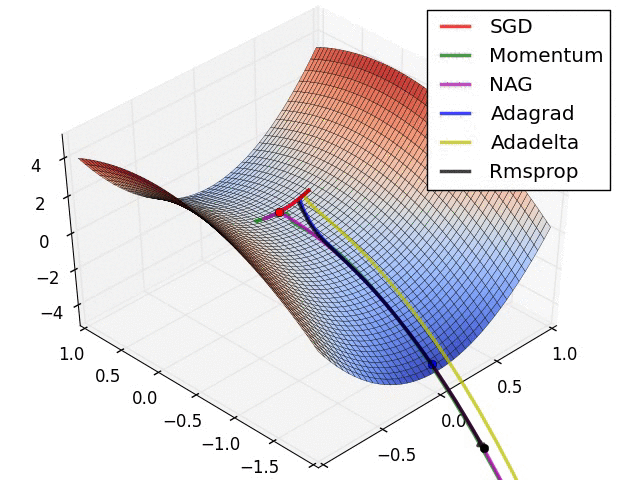
对上述算法的说明【2】:
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 
? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
查看queue中,queue相关的内容,了解tensorflow中队列的运行方式。
| 操作 | 描述 |
|---|---|
| class tf.train.Coordinator | 线程的协调器 |
| tf.train.Coordinator.clear_stop() | 清除停止标记 |
| tf.train.Coordinator.join(threads=None, stop_grace_period_secs=120) | 等待线程终止 threads:一个threading.Threads的列表,启动的线程,将额外加入到registered的线程中 |
| tf.train.Coordinator.register_thread(thread) | Register一个用于join的线程 |
| tf.train.Coordinator.request_stop(ex=None) | 请求线程结束 |
| tf.train.Coordinator.should_stop() | 检查是否被请求停止 |
| tf.train.Coordinator.stop_on_exception() | 上下文管理器,当一个例外出现时请求停止 |
| tf.train.Coordinator.wait_for_stop(timeout=None) | 等待Coordinator提示停止进程 |
| class tf.train.QueueRunner | 持有一个队列的入列操作列表,用于线程中运行 queue:一个队列 enqueue_ops: 用于线程中运行的入列操作列表 |
| tf.train.QueueRunner.create_threads(sess,? coord=None, daemon=False, start=False) | 创建运行入列操作的线程,返回一个线程列表 |
| tf.train.QueueRunner.from_proto(queue_runner_def) | 返回由queue_runner_def创建的QueueRunner对象 |
| tf.train.add_queue_runner(qr, collection=’queue_runners’) | 增加一个QueueRunner到graph的收集器(collection )中 |
| tf.train.start_queue_runners(sess=None, coord=None, daemon=True, start=True, collection=’queue_runners’) | 启动所有graph收集到的队列运行器(queue runners) |
class tf.train.Coordinator
tf.train.Coordinator.stop_on_exception()
参考:







